
That's the concurrent call problem. It's not new. It's existed since the first telephone switchboard, and for most businesses, it has never been solved. Until now.
The direct answer: AI receptionists handle an effectively unlimited number of simultaneous calls. Each incoming call spins up its own independent processing session on cloud infrastructure. There's no queue, no busy signal, no "please hold." Whether two calls arrive or two hundred, every caller gets an immediate answer.
This article explains how that works, why it matters, and what to watch for when evaluating AI receptionist plans.
Key Takeaways
- Every inbound call gets its own isolated AI session — no hold music, no queue, no busy signal
- Human receptionists are hard-capped at one conversation at a time; doubling capacity means doubling headcount
- Response quality holds steady whether the AI is handling 2 calls or 200 at once
- "Unlimited concurrent" doesn't mean unlimited minutes — your plan's monthly usage cap is a separate constraint
- Call spikes from marketing campaigns, weather events, and seasonal surges are where this capability pays off most
How AI Receptionists Handle Unlimited Simultaneous Calls
The Architecture Behind Instant Answers
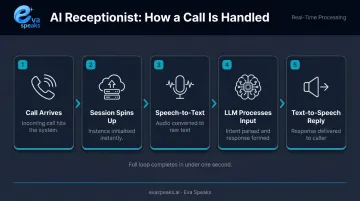
When a call hits an AI receptionist system, nothing gets routed to a shared agent pool. Instead, the platform spins up a fresh, isolated session for that specific caller. EvaSpeaks follows this session-based model — each inbound call gets its own LLM processing context, which means the hundredth concurrent caller receives the same immediate, context-aware response as the first. Here's the sequence:
- Call arrives at the business number
- New session spins up — dedicated compute resources assigned to this caller only
- Speech-to-text (STT) converts the caller's voice into text in real time
- LLM processes the input using the business's configured call-flow context (scripts, routing rules, FAQs)
- Text-to-speech (TTS) delivers the AI's reply — the whole loop completing in well under a second
The fifth caller arriving at the same millisecond as the fourth gets the same experience. There's no shared bottleneck because the architecture doesn't work that way.
What "Horizontal Scaling" Actually Means
That session-based architecture is only possible because of how cloud infrastructure scales. A traditional phone bank has a fixed number of lines — fill them all, and the next caller gets a busy signal. Cloud infrastructure expands on demand instead, spinning up additional independent processes as volume climbs. That's horizontal scaling in practice.
For practical purposes, this means the concurrent limit for a small or mid-sized business is essentially unreachable in day-to-day operations. True infrastructure ceilings exist, but they're measured in thousands of simultaneous calls — volumes most SMBs will never approach. This is also why platforms like EvaSpeaks can be positioned as an alternative to hiring additional reception staff: the technology absorbs call spikes that would otherwise require proportional headcount increases, without the overhead of enterprise-grade infrastructure.
Response Speed Under Load
Modern AI voice systems are fast. OpenAI reported GPT-4o audio responses as low as 232 ms, with a 320 ms average — compared to older voice pipelines that averaged 2.8 to 5.4 seconds. Production voice AI platforms typically target 800 ms or lower for end-to-end response time. Because each call runs on isolated compute, this speed doesn't degrade as volume climbs. The hundredth simultaneous call is just as fast as the first.
Customizable Call Flows Run Per Session
Each session doesn't just answer — it answers according to the business's specific configuration. Eva Speaks lets businesses define call-flow scripts, routing rules, and office hours that govern every interaction. Within each session, that logic executes independently, handling whichever task applies:
- Answering an FAQ
- Capturing a message
- Routing to the right department
- Escalating an urgent situation
No call's handling is delayed or affected by what's happening in any other concurrent session.
See it handle multiple live calls at once. Request Live Demo
Here is how AI receptionists, human receptionists, and IVR queue systems compare when handling simultaneous call volume:
| AI Receptionist (EvaSpeaks) | Human Receptionist | IVR Queue System | |
|---|---|---|---|
| Features | Unlimited concurrent calls, full AI conversation, CRM sync | One call at a time, full interaction | Queues callers, plays hold music, basic routing |
| Best-fit Business Size | Any business with call spikes | Very small operations | Any size with high inbound volume |
| Key Strengths | No calls dropped or queued, infinitely scalable | Full human quality | Manages overflow, familiar caller experience |
| Implementation Complexity | Low | None (hire) | High |
| Integration Capability | CRM, scheduling, EHR native | Manual | Limited |
AI vs. Human vs. Traditional Answering Service: A Capacity Comparison
Side-by-Side at a Glance
| Dimension | AI Receptionist | Human Receptionist | Traditional Answering Service |
|---|---|---|---|
| Concurrent capacity | Effectively unlimited | 1 call at a time | Limited by staffed agents |
| Response under peak load | Consistent, sub-second | Degrades as volume rises | Queue forms; callers wait |
| Overflow behavior | No overflow — every call answered | Hold queue or voicemail | Hold times of 30–90 seconds |
| Cost to double capacity | None | Double headcount | Add more agents |
The Staffing Math Problem
A human receptionist can physically hold one conversation at a time. Handling 5 simultaneous calls requires 5 people available at that exact moment.
The cost of that capacity adds up fast. According to the Bureau of Labor Statistics, the median receptionist wage was $17.90/hour — $37,230 annually — as of May 2024, not counting benefits. Total compensation for office and administrative support roles averages $35.96/hour when benefits are included. Scaling to handle call spikes means carrying payroll for peak scenarios that may only occur a few times per month.

What Happens When Capacity Is Exceeded
Callers don't wait patiently. Research from Invoca found that 26% of calls from potential customers went unanswered across industries — and those aren't calls to voicemail that get returned. They're sales opportunities that evaporate.
Longer waits produce higher hang-up rates. HDI data shows global service desk average speed of answer averaged 98 seconds, with peaks reaching over 500 seconds. Callers who hang up mid-hold rarely call back at the same rate.
That lost volume problem compounds when the calls that do connect also suffer — which is what happens when agents are stretched thin.
Response Quality Doesn't Degrade Under Load
Human agents under high call volume get stressed, rush through conversations, and deliver uneven experiences. The BLS notes that managing numerous phone calls is a recognized source of stress for receptionists. AI doesn't have that problem. The quality of response on a busy Monday morning is identical to a quiet Thursday afternoon — same accuracy, same tone, same handling logic.
See how businesses in your industry are using concurrent AI calling. See Industry Use Cases
When Unlimited Concurrency Makes the Biggest Business Difference
Call Spike Scenarios That Break Human Models
Some businesses operate at relatively steady call volumes. Others face predictable — or unpredictable — surges where calls cluster into narrow windows:
- Post-campaign launches: A radio ad or email blast drives 20 calls in 10 minutes. Human capacity can't flex in time.
- Weather-driven emergencies: HVAC, plumbing, and roofing businesses see demand surge after storms. ServiceTitan found that summer heat waves increased average daily HVAC revenue by 55% — and the calls that capture that revenue all come in at once.
- Seasonal peaks: Tax season, open enrollment, holiday retail, real estate listing surges — all create predictable windows where concurrent capacity matters most.
- Marketing-driven spikes: Any campaign that works creates a call spike. The businesses that can answer all of them win the campaign's full ROI.
Speed Wins the Lead
When multiple callers reach your line in the same minute and only one can be answered, the others are functionally calling your competitors. Harvard Business Review analyzed 2,241 U.S. companies and found that firms contacting leads within one hour were nearly 7x more likely to have meaningful conversations with decision-makers than those who waited longer. Concurrent capacity is what makes that response speed possible at peak volume.
Multi-Location and Franchise Use Cases
For businesses running multiple locations, the capacity math multiplies. Each location brings different call volumes, peak windows, and routing requirements. A single AI system can field calls across all of them simultaneously — no additional staffing required, each location's calls handled to its own configuration.
This is where configurable routing becomes critical. Systems like Eva Speaks allow different call flows for different locations, departments, or call types — each running simultaneously, independently, without one affecting the others.
Watch how AI manages a high-volume call flow in real time. Watch AI Call Flow Demo
Concurrent Calls vs. Monthly Call/Minute Limits: What's the Real Constraint?
Most AI receptionist plans govern two distinct things — and conflating them leads to choosing the wrong tier.
| Constraint Type | What It Controls | When It Bites You |
|---|---|---|
| Concurrent call limit | How many calls can be active at the same time | During sudden volume spikes — callers hit a queue or get dropped |
| Monthly usage limit | Total minutes or calls consumed per billing period | At month-end, when overages kick in or service throttles |
A Concrete Example
Eight calls arrive simultaneously during a Monday morning rush. Each lasts 4 minutes.
- Concurrency result: All 8 callers answered immediately, no one waits
- Usage result: 32 minutes drawn from the monthly plan (8 × 4 minutes)

The concurrency worked perfectly. Whether 32 minutes strains your plan depends on your tier — but that's a separate question from whether calls were answered.
What to Check When Evaluating Plans
When comparing AI receptionist providers, ask these specific questions:
- Does this plan impose a hard cap on simultaneous calls? (A red flag for any business with unpredictable volume)
- Is the only usage constraint total monthly minutes or call count?
- What happens if I exceed monthly limits — per-minute overage, or service interruption?
- At which plan tier does concurrent capacity become adjustable?
Some providers like Retell and Vapi explicitly document concurrent call slots and separate them from usage pricing. Others bundle everything into monthly call or minute packages. Before signing up, identify which constraint actually applies to your call patterns — that determines whether a plan will hold up on your busiest day, not just your average one.
Does Call Quality Drop When Handling Many Calls at Once?
No, at least not for properly architected systems.
Each call session runs on its own dedicated compute resources. The AI isn't dividing attention across sessions the way a human would if asked to manage three conversations at once. There's no cognitive load, no fatigue, no degradation from high volume.
According to a recent AssemblyAI analysis, modern speech recognition exceeds 90% accuracy in optimal conditions, with phone conversations typically ranging 80–88%. Contact center automated systems are generally designed to meet a 90%+ threshold for routine interactions. That accuracy holds whether the system is processing one call or one hundred simultaneously.
That consistency is where AI diverges most sharply from human agents. Peer-reviewed research on contact center work consistently links high call volume to increased stress, emotional dissonance, and burnout — factors that directly degrade individual interaction quality. AI doesn't experience any of that. The caller who reaches the system during a peak surge gets the same experience as the caller during a quiet period.
Hear how consistent AI sounds on a real call. Listen to Sample AI Call
Frequently Asked Questions
How many simultaneous calls can an AI receptionist handle?
AI receptionists handle an effectively unlimited number of simultaneous calls by spinning up an independent session for each incoming call on cloud infrastructure. For virtually all small and mid-sized businesses, there is no reachable concurrent limit — actual infrastructure ceilings exist only at enterprise-scale volumes most SMBs will never approach.
Can an AI receptionist greet callers professionally?
Yes. AI receptionists deliver a customizable greeting to every caller the moment the call is answered with no delay or hold. The greeting can include your business name and adapt based on call type or time of day, depending on how the system is configured.
Does call quality suffer when many calls come in at the same time?
No. Each call runs on isolated compute resources, so the AI's accuracy and response quality don't degrade under high concurrent volume. This is a meaningful difference from human agents, who demonstrably slow down and make more errors under heavy call loads.
What's the difference between concurrent call capacity and monthly call limits?
Concurrent capacity determines how many calls can be answered at the exact same moment. Monthly limits cap total usage (minutes or calls) over a billing period. They're independent variables. "Unlimited concurrent" means no caller waits; it says nothing about how many total minutes your plan includes.
What industries benefit most from unlimited concurrent call capacity?
Industries with unpredictable or weather-driven demand spikes benefit most: HVAC, plumbing, and roofing (storm surges), real estate (new listing activity), healthcare and dental (open enrollment pushes), and multi-location service franchises managing aggregate call volume across sites.
Is there any scenario where an AI receptionist would miss a call or give a busy signal?
With cloud-native AI systems, busy signals due to concurrent volume shouldn't happen. The realistic culprits for a missed call are misconfigured call forwarding, number routing errors, or a rare infrastructure outage — not call volume.


